
Data
Scholars of early modern English drama have new ways of working with data—and new reasons to do so. A Digital Anthology of Early Modern English Drama (EMED) supports this work with encoded texts and structured bibliographic materials. Below are some entry points into the EMED project, through textual data, network data, and metadata, that allow us to do interesting new work with these centuries-old texts. You will also find the rules that we followed in encoding the plays; datasets for analysis; and tools and resources to help you get started.
Data in EMED
Data, in the broadest sense, can be defined simply as things that are known, or items of information. In the humanities, data can take many forms. A Digital Anthology of Early Modern English Drama contains primarily two types of structured data:
- textual data, or machine-readable texts, which contain additional markup and may be analyzed on their own or grouped into a corpus.
- network data, or information about the relationships among facts, such as the fact that person A is the son of person B.
For EMED, the first type includes the texts of the plays, encoded with additional information about elements such as stage directions and the words spoken on stage; divisions of the playbook, including paratexts, prologues, acts, and scenes; and parts of speech. The second type refers to information about a play and its associated authors, printers, acting companies, publication date, genre, and so on. This information is known as metadata, which literally means data about data.
While you can read about individual plays on their play page (and download them there in XML, PDF, and HTML), below you’ll find links to download the full metadata file for the entire site, as well as batch-download plays encoded in XML. We have pre-processed some of the XML files to show the potential of the markup for early modern plays.
Encoding plays
Computers are extremely literal. For them to interpret textual data, it needs to be encoded, or tagged with additional information telling the computer what the words mean—and indeed, that a string of character is a word. Humans are highly variable: do you want to tag a title to a song as a <head>, a <label>, a <title>, or just as part of a paragraph <p>? We do best when we have a guide to help us agree how to tag something consistently. EMED follows the Text Encoding Initiative guidelines for eXtensible Markup Language (XML). These guidelines still allow for a great deal of adaptation. Our encoding policy details specific decisions we make on how to treat original and regularized spellings, illegible words, the attribution of speeches and the representation of stage directions, and other elements of the text. In the above example, we'd use <label> to encode a title of a song found in a EMED play, and use <head> for act and scene headings.
Download a PDF of our encoding documentation. For further information on our editorial choices, see our Editing page.
Challenging Conventions: The Problem of Ben Jonson

When considering the featured plays for A Digital Anthology of Early Modern English Drama, we hoped to include several plays by Ben Jonson. The Alchemist, Bartholomew Fair and The Staple of News were all attractive possibilities. But the Shakespeare His Contemporaries project chose a different edition of The Alchemist to encode, leaving us without their substantial assistance in adding parts-of-speech tagging and other encoding. That made the play a bad candidate for further correction and encoding. With Bartholomew Fair and The Staple of News, different kinds of encoding challenges emerged. Unlike other contemporary folios of plays, Jonson’s folio was printed in a single column, creating lines that were far longer than any other play we edited. This in itself would have been difficult to render in a readable version on many screens. We know Jonson was involved in the printing of his plays. He and his printers also experimented with representing simultaneous speech on the page. In places, they introduced two columns to allow characters to speak at the same time, actively interrupting each other. Adding even more challenges for the Jonson encoder, his stage directions were presented as marginal notes—and encoded as such by the EEBO-TCP transcribers whose work EMED builds on. His stage directions also often lack the sign-posting that typifies other early modern playbooks, words such as “enter” and “exit” that we relied on for algorithmic processing.
We have prepared proofed transcriptions of Bartholomew Fair and The Staple of News. But we have not yet reconciled Jonson’s innovative representation of simultaneous speech and stage action with the linear nature of XML. As time affords, we intend to take up the further encoding challenges of these plays. In the meantime, we are happy to provide the proofed transcriptions to anyone who would like to tackle them. Please contact us through our feedback form for details.
Mapping characters in richly encoded plays
Visualizations allow us to see texts in new ways. Creating new views onto the text can be useful to reveal unseen patterns, confirm expectations arrived at through a different method, highlight differences and similarities across texts, and even identify errors or inconsistencies that need to be fixed.
The encoding underlying EMED Featured Plays is extremely rich. For example, every word is marked up with XML tags rather than just every line or every speech. This makes the XML more difficult to read for humans, but easier to read and process for computers. In-depth encoding allows one to ask interesting analytical questions of these plays that might not otherwise be possible. Every speech in the thirty EMED Featured Plays has been tagged with a standardized name (or names) to show who delivers it. This means you could easily pull out all speeches by a certain character, no matter how they are referred to in the printed speech prefix. This is especially useful for early print editions, where speech prefixes are often missing or ambiguous.
For the subset of plays by Christopher Marlowe, EMED editors went one step further and added these ‘who attributes’ to stage directions as part of an effort to encode the entrances and exits of all characters. This allows us to map the movement of characters through the play, creating a new view on the text.
Take a look at the links below – what can you tell about these plays just from the mapping? What strikes you as interesting or worthy of a closer look? What is gained by this view, and what is lost? What groupings and character types become apparent? Tip: you can drag the character names into any order you like.
Character charts
- Doctor Faustus Character Chart
- Dido Character Chart
- Tamburlaine, part 1 Character Chart
- Tamburlaine, part 2 Character Chart
- Jew of Malta Character Chart
- Edward the Second Character Chart
- Massacre at Paris Character Chart

Red line: act or scene change specified in text
Orange line: stage cleared of characters (helpful for playbooks with no scene divisions)
Analyze it yourself
You can download the XML files used to produce the character charts above here.
Note that these files differ from EMED version 3 files in that stage direction tags are given “who attributes” that specify who enters and exits, and also include <move> tags which provide entrances and exits that are not specified explicitly in printed stage directions.
Encoding as editing
This work represents an extra layer of editorial decision-making, because it is not always clear who remains onstage and who departs. Specifying this in the XML makes demands on editors that are not always required in a print edition. Issues that remain open to interpretation and to performance decisions have to be pinned down when one decides to encode all entrances and exits; these could be the point at which a messenger exits, when unnamed characters are the same or different individuals, when characters die and when their bodies are removed, and many other points of entry and exit that are not specified. When doing this interpretive work, we have not supplied additional written stage directions within the body of the text, because these editions remain primarily documentary representations of the earliest printed witness to the play. Instead, we have added this information behind the scenes, in
Single witness editions
When looking at visualizations or analytical representations of texts one must always be aware of the particular qualities and limits of the texts under examination. The character mappings above might look different for a modern critical edition because EMED texts are single witness editions; that is, they are based on one print copy, with regularized spelling but no substantial corrections. For more discussion of early printed playbooks, see our Editorial resources page. You should be aware of the idiosyncrasies and potential for error or inconsistency in early print before drawing conclusions from these charts. For example, in Edward II, there is a confusion in the print between the Earl of Arundel and Matrevis. Often, editors conflate these characters into the single Earl of Arundel in the first half of the play, and take the Matrevis who appears towards the end of the play to be a wholly different character. We have not attempted to reconcile or correct these in our assigning of who attributes, and therefore readers will want to be aware of this issue as they consult the character map.
Datasets and downloads
Metadata
Download the EMED Metadata.
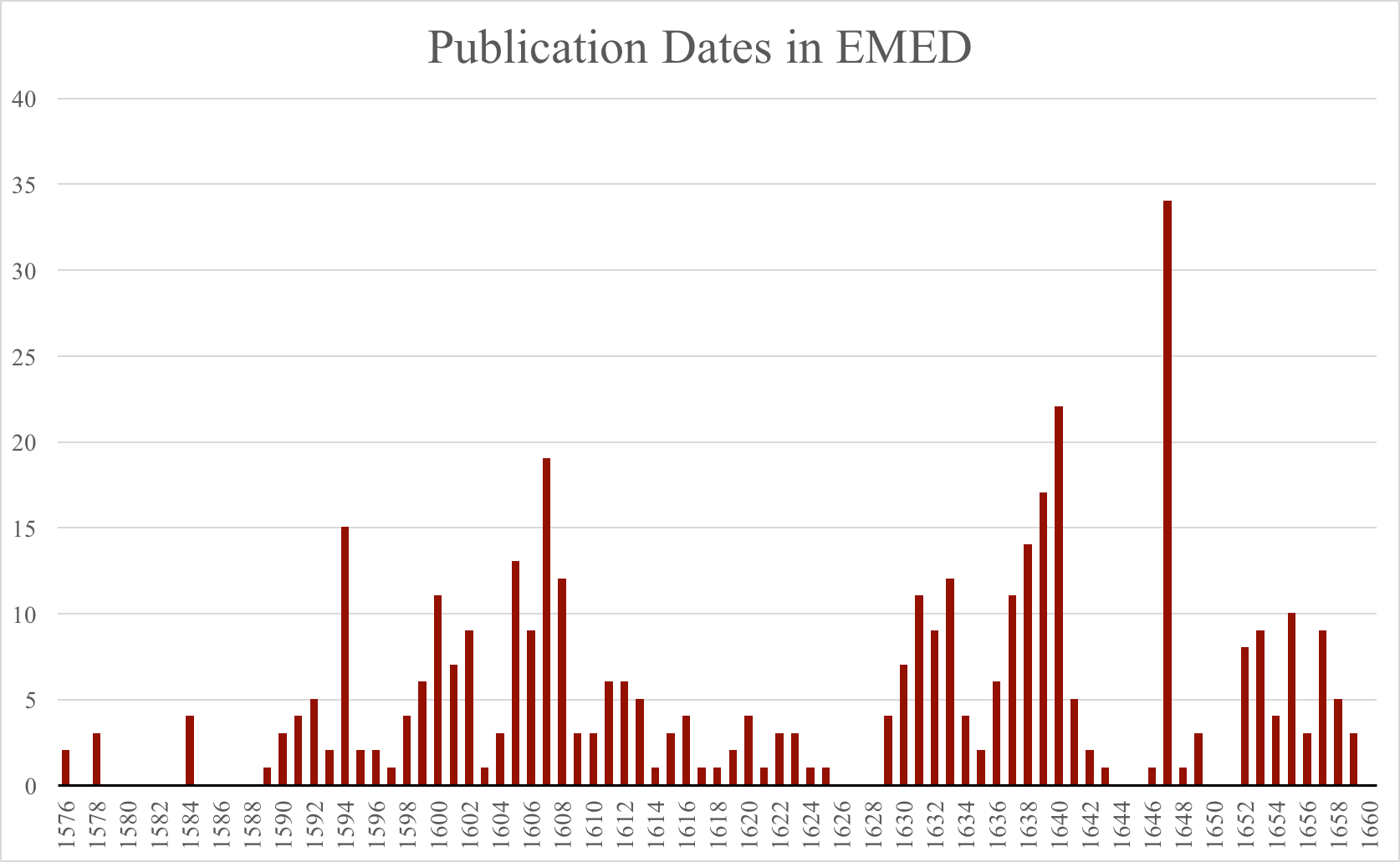
EMED’s metadata consists of information about the play, such as the author, printer, publisher, bookseller, place of publication, physical features of the playbook, information about the first performance, and more. This information may be searched and browsed online, or downloaded as a .csv file. CSV files can be examined in a variety of spreadsheet software, such as Excel, or uploaded to Open Refine for processing and analysis. The limits of the EMED corpus are important to consider when analyzing or visualizing this data: we include only a fraction of the drama performed in London during this period, excluding university plays, closet dramas, and most masques, which were performed by the court. Additionally, our corpus only contains first editions. It may be fruitful for those interested in publication dates and popularity to compare our data to that of the Database of Early English Playbooks (DEEP). You can download performance and publication data for the EMED corpus here: EMED-dates.xlsx.
Corpus download
Use our Corpus Download page to download all or a selection of files of the plays.
You may want to work with a selection or all of the available EMED texts offline. You can easily search and download them in bulk using our Corpus Download function. First, select one of four groups of texts you wish to work with: the TCP files as hosted by EMED, the Shakespeare His Contemporaries files, the EMED fully encoded Featured Plays, or the EMED minimally encoded files (to be made available in due course). You can learn more about how our documentary editions use and adapt the files produced by these projects on our Editing page.
Note: a play may not have XML files for each type (TCP, SHC, EMED). For example, if it was not part of the EEBO-TCP’s Phase 1, it may not have a TCP file, but may still be provided by SHC. Once you’ve selected your XML type, you may define your corpus with our search engine. You may select one, part, or all of your results to download as a group.
Spoken text
You can download text files of the spoken text in Marlowe’s plays here. When thinking about new ways to process the plays, one of the first things to decide is what you’re taking as ‘the play’; you may not want to include the prefatory printed material, our textual notes, or even the speech prefixes or stage directions. Accordingly, in this Data Download, we have provided the plays by Christopher Marlowe as spoken text only, and in regularized rather than original spelling format. Try pasting these into a word cloud generator or text analysis tool like Voyant Tools to explore word use in these plays more deeply: https://voyant-tools.org .
Parts of speech
The ana attribute (@ana) in TEI encoding allows the encoder to designate an analytical feature of a specific portion of a text. In our case, we use it to provide parts of speech to individual words—that is, whether a word is a proper noun, an adjective, a participle, a present-tense verb, or so on. This work is automatically done by the SHC project using MorphAdorner, and is lightly adjusted by EMED editors, though we do not guarantee its accuracy. A python script allows us to create a list of words with a given ana attribute, making a list with their original and regularized spellings and their word ID, which designates their place in the text.
The following .txt files are tab-delineated lists of the proper nouns found in each play, with their word IDs, original spelling, and regularized versions. For programs that can help manipulate this data, see Tools and Projects below.
Proper nouns in Dido: Dido-nouns.txt (includes possessives, both plural and singular)
Proper nouns in Tamburlaine 1: 1Tam-nouns.txt (includes possessives, both plural and singular)
Proper nouns in Tamburlaine 2: 2Tam-nouns.txt (includes possessives, both plural and singular)
Proper nouns in Doctor Faustus: DrFaust-nouns.txt (includes possessives, both plural and singular)
Proper nouns in Edward II: Ed2-nouns.txt (includes possessives, both plural and singular)
Tools and projects
Folger Digital Texts: Free access to meticulously accurate texts from the Folger Shakespeare Library editions of Shakespeare’s plays and poetry, including free downloads of the source code—providing the basis for new noncommercial projects and apps.
Folger Digital Texts API: A work-in-progress API that provides a variety of views, analyses, and visualizations of Shakespeare’s plays, including cue scripts and graphical representations of who is on stage across a timeline of the play.
Open Refine: Formerly known as Google Refine, this tool allows you to upload data sets (such as the tab-delineated txt files above), clean the data, explore it quickly and easily, and transform it into new formats.
- If you’re new to Open Refine, there are several tutorials available:
- Not just for librarians, Library Carpentry’s Open Refine lesson walks you through uploading data, cleaning it, using features of Open Refine, and reconciling your data against external references.
- Cleaning Data with Open Refine This lesson from The Programming Historian focuses on data cleaning: recognizing and removing duplicates, separating multiple values in the same field, analyzing distribution of values, and grouping values.
Digital Tools for Textual Analysis (Folgerpedia): This is a list of digital humanities tools dealing with textual analysis, most of which were initially compiled by Brett Greatley-Hirsch, Heather Froehlich, and other participants of the Folger Institute's Early Modern Digital Agendas (2013) institute for advanced topics in digital humanities.
Early Modern Print: Text Mining Early Modern Printed English: An online suite of tools and projects for the computational exploration and analysis of English print culture before 1700. This group of tools takes advantage of the Text Creation Partnership’s transcriptions of early modern printed works to facilitate quantitative approaches to early modern English texts.
Authority files are external reference lists that help establish a rule for identifying a person, place, or thing. Below are a series of databases outside of EMED which may be useful as references for the people and places found in EMED texts.
- GeoNames: A geographical database that provides latitude and longitude for use with GIS applications.
- VIAF: The Virtual International Authority File: Combines name authority files from the majority of the major libraries in the world, including the Library of Congress.
- MoEML Gazatteer of Early Modern London: Digital gazatteer and authority list for early modern London, part of the Map of Early Modern London project.